Kubelet的功能简单总结就是根据系统中pod的变化,来处理pod的生命周期。它向下通过底层docker等接口处理pod的启动 更新停止,它向上通过list watch获取pod的信息来做任务识别和分发。这一节主要总结下kubelet三个数据来源合并的过程,代码参考1.7版本,是17年写的了,最近整理搬运到博客。
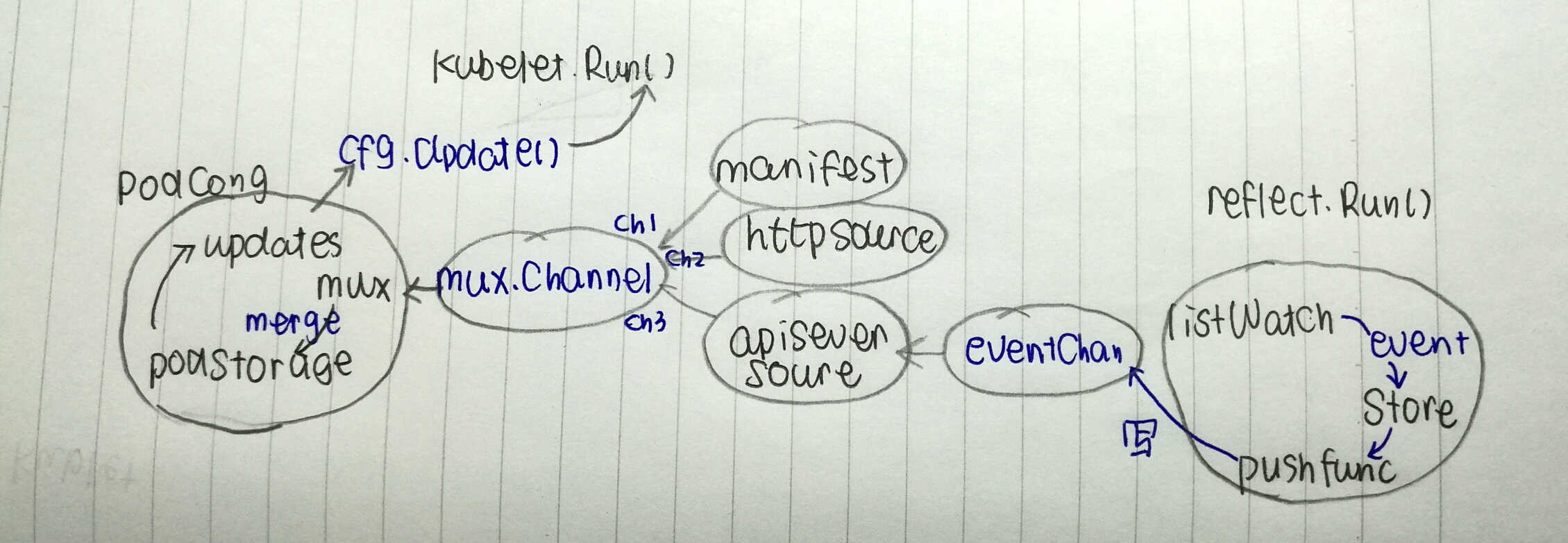
kubelet的Pod来源有三个,分别是manifest http以及apiserver。三者通过mux提供的三个channel给mux发送event。mux中开启三个协程去分别处理每种source到来的event,也就是pod。mux的处理过程就是将chan上收到的pod交给podstorage去merge。merge的过程就是跟本地的pod缓存比较,然后分解出不同事件往podstorage的update chan上统一的发送事件。这个chan通过Updates()方法被kubelet.Run使用。
Kubelet的启动
Kubelet的工作原理是通过三种途径获得Pod,由KubeletBootstrap实现的Run方法根据事件种类的不同来分发和处理Pod。其中连接具体工作和Pod来源的通道是podCfg.Updates()返回的chan。今天总结下ListWatch结果和Kubelet主线程之间通信的过程。
1 | func startKubelet(k kubelet.KubeletBootstrap, podCfg *config.PodConfig) { |
在函数makePodSourceConfig中PodConfig通过cfg.Channel合并了三种Pod的来源,包括放在固定目录的manifest,以及HTTP请求,以及ListWatch获得的Pod变化。
1 | func makePodSourceConfig(...) (*config.PodConfig, error) { |
PodConfig的实现
podStorage
storage是Pod的全部缓存,其中包含有updates这个chan,且storage负责单向向chan上写数据,即更新Pod的结果。这个chan通过PodConfig的Updates()方法对外提供读取chan上Pod的信息的方法,没有读取将阻塞。
1 | type PodConfig struct { |
1 | func (c *PodConfig) Updates() <-chan kubetypes.PodUpdate { |
podStorage实现了Merge接口,提供Merge(source string, change interface{})方法。它识别从不同源来的change事件,并根据change 的类型对pod进行merge。如果是apiserver源的Pod,最终类型都是SET,这时从storage中读取的pods为oldPods,跟change中的所有合法的newPods比较,如果oldPods中没有则属于AddPods,如果oldPods有则决定是需要update还是reconcile还是delete。另外如果oldPods中有而newPods中没有则removePods。操作podstorage的过程podLock要上锁。
1 | updatePodsFunc := func(newPods []*v1.Pod, oldPods, pods map[types.UID]*v1.Pod) { |
从不同Pod源整理出remove, add, update, delete的Pod后,依次往podstorage的updates chan上写数据,这个过程updateLock要上锁。
mux
mux用于实现源合并,它维护了每种source对应的chan,并通过Channel(source string)方法返回。该方法同时开启一个listen的goroutine,一旦这个chan上有数据写入,就读取并通过mux的merge进行合并。也就是这个podstorage的数据来源是mux暴露给外界的,让不同源可以写入的。
1 | func (m *Mux) Channel(source string) chan interface{} { |
这个chan通过PodConfig的Channel方法提供给外部使用,每种源通过cfg.Channel(sourceName)来写入数据到mux,mux通过merge最终将数据合并到podStorage。
1 | func (c *PodConfig) Channel(source string) chan<- interface{} { |
apiserver源的实现
如上所述,updates是一个允许每个源单向写入的chan。APIServer这个源通过reflector来实现对Pod对象的ListWatch,它通过client-go/tools/cache这个包提供对reflector的实现。
1 | func NewSourceApiserver(c clientset.Interface, nodeName types.NodeName, |
Reflector
reflector对象主要的成员就是listerWatcher,store则是NewReflector外部的store,reflector就是把list和watch到的结果set到store里面。reflector.Run() 开启新协程去执行ListAndWatch()。
1 | type Reflector struct { |
list会触发一次store的同步,在syncWith中执行store.Replace,并记录这次同步的resourceVersion。之后将开启goroutine去处理定时同步。在开启的watch循环中,设置watch的options包括resourceVersion和timeout时间。这里reflector为了避免watcher的挂起,设置了timeout时间,它会停止在该时间窗内不能获得任何事件的watchers。Watch最后返回的接口提供两个方法,可停止Watch,可从中获取Watch事件。
1 | type Interface interface { |
当无错误建立起watch通道,获得watch.Interface后,reflector调用watchHandler去处理。它就是从ResultChan中获取事件更新到store,同时更新resourceVersion。
1 | func (r *Reflector) watchHandler(w watch.Interface, resourceVersion *string, |
UndeltaStore
reflector最终操作的store,kubelet中使用的是UndeltaStore,它是Store的一层封装,加入了PushFunc。在每次Add或UpdateDelete操作时,都执行注册的PushFunc将完整的Store.List() Push出去。这里的PushFunc是往apiserver源的chan上push数据。
为什么要完整的store.List,而不是只push增量呢。
1 | type UndeltaStore struct { |
这里的Store是个实现增删改查等方法的接口,它是线程安全的Store的一层封装,对外提供对单一对象obj的接口,通过keyfunc从obj提取存储的key值,而ThreadSafeStore则提供根据key-value更新存储的接口,比如Add(key string, obj interface{}),其中ThreadSafeStore通过treadSafeMap实现的。
1 | // NewStore returns a Store implemented simply with a map and a lock. |
Question
- reflector的store当中pushfunc为什么每次push所有的store,而不是只取增量。
- updates chan阻塞会发生什么