CSAPP ch12总结了三种并发模型:基于进程,基于IO多路复用,基于线程。在实际的服务器应用中基于线程的并发模型并不能创建和使用过多的thread。因为thread数目过多于CPU核数,内核调度和切换thread将付出较大代价。因此通常在基于线程的基础上,在用户态设计用户态线程模型与调度器,使得调度不需要陷入内核完成,减小并发调度代价。
调度器的设计与演化
用户态线程模型又根据多少个协程对应OS内核线程区分为1:1 M:1 M:N 三种。go在runtime层实现的是M:N的用户态线程+调度器,它结合了前两者的优势 充分利用多核+更小的上下文切换调度代价。经过Go几个版本的演化,调度器模型从最初的G-M模型今天的G-P-M模型已经基本固定。本节总结了G-P-M如何解决了G-M存在的问题。
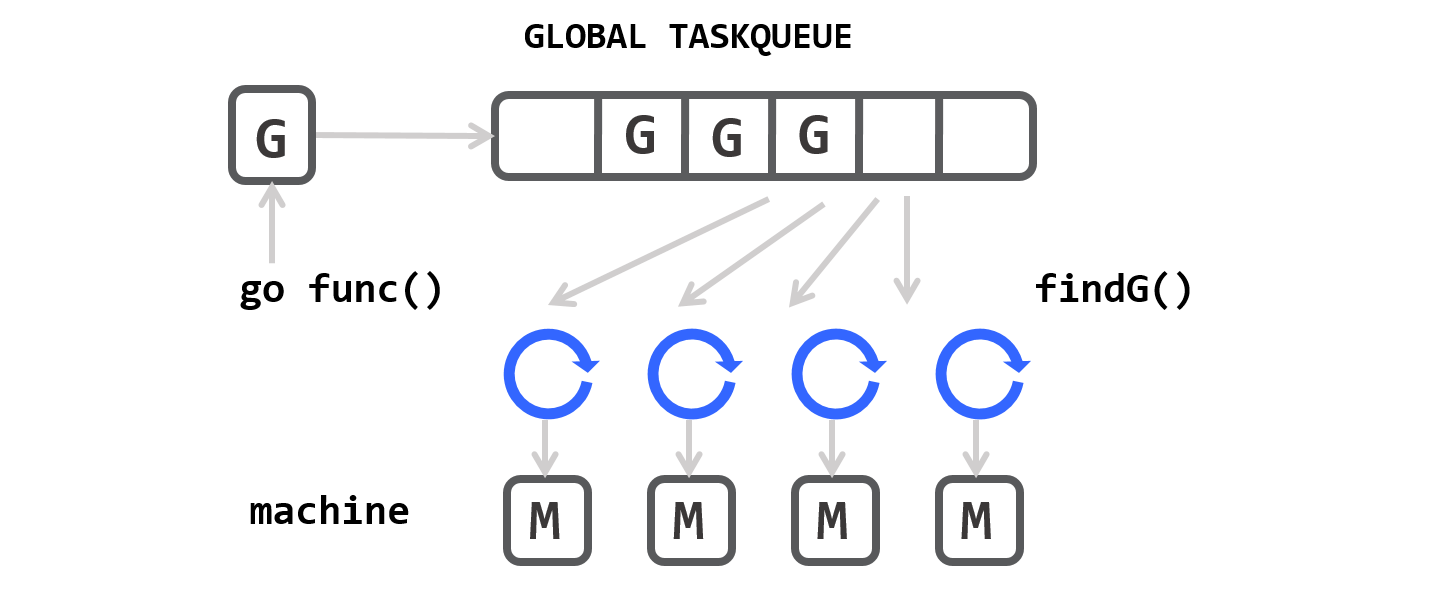
G-M Model
Go 1.0版本实现的调度器就是M:1的 线程池+任务队列的形式。每条内核级线程运行一个M,每个M不停地从任务队列shed中取出任务G并执行。任务队列中的任务G就是通过go关键字创建出goroutine。Scalable Go Scheduler Design 指出这样的调度器设计上的一些问题。
- 所有G操作都由单个全局锁
sched.Lock保护,测试发现14%的时间浪费在了runtime.futex()。 - 当M阻塞时,G需要传递给别的M执行,这导致延迟和额外的负担。
- M用到的
mCache是属于内核线程的,当M阻塞后相应的内存资源仍被占用着。 - 由于syscall造成的过多M阻塞和恢复。
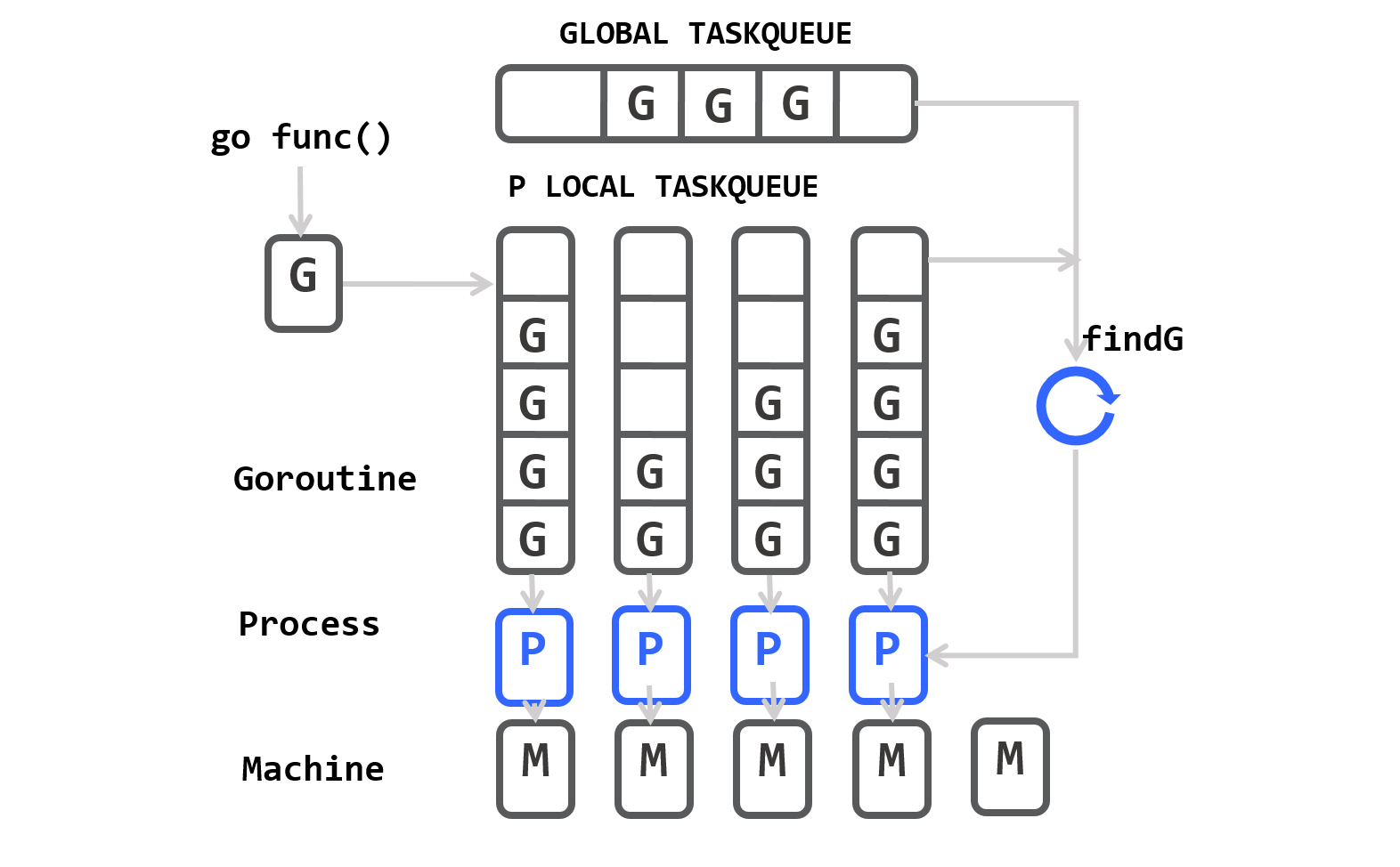
G-P-M Model
为了解决上面的问题,Go1.1以后通过work stealing算法实现了M:N的G-P-M模型。它通过引入逻辑Processer P来解决G-M模型的几大问题。
- P优先从本地G队列中获取任务执行,这个操作线程安全不用Lock。
- G存在于P队列中。当某个M陷入系统调用时,P将与M解绑定,并找另外的M(或创建新M)来执行G的代码,避免G在M之间传递。
- P给M运行提供了运行所需的mCache内存,当PM解绑时将收回内存。
Data Structure
G代表goroutine,它通过go关键字调用runtime.newProc创建,创建后即被放在P本地队列或全局队列中,等待被执行。它存储了goroutine执行的栈信息,状态,任务函数。其中执行的func入口保存在startPC域。由于它可以被任何P获取并执行,G在stack字段保存了goroutine栈的可用空间。在sched域保存了goroutine切换所需的全部上下文。
1 | type g struct { |
P代表processer,数目为GOMAXPROCS,通常设置为CPU核数。P不仅维护了本地的G队列,同时为M运行提供内存资源mCache,当M陷入阻塞的系统调用导致P和M分离时,P可以回收内存资源。P在本地runq中取任务G执行时不用lock,但是从别的P中stealG或从全局队列中获取G时需要lock。当有新的G加入到队列时,会试图唤醒空闲的P。如果有空闲的P,会试图找空闲的M或创建新的M来执行,也就是说M是按需创建的。
1 | type p struct { |
M表示machine,其中mstartfn是M线程创建时的入口函数地址。当M与某个P绑定attached后mcache域将获得P的mCache内存,同时获取了P和当前的G。然后M进入schedule循环。shedule的机制大致是:
- 从当前P的队列、全局队列或者别的P队列中
findrunnableG - 栈指针从调度器栈m->g0切换到G自带的栈内存,并在此空间分配栈帧,执行G函数。
- 执行完后调用goexit做清理工作并回到M,如此反复。
如果遇到G切换,要将上下文都保存在G当中,使得G可以被任何P绑定的M执行。M只是根据G提供的状态和信息做相同的事情。
1 |
|
全局的任务队列保存了空闲m和空闲p的链表,以及全局G队列链表。
1 | type schedt struct { |
Go调度器解决的问题
阻塞问题
如果任务G陷入到阻塞的系统调用中,内核线程M将一起阻塞,于是实际的运行线程少了一个。更严重的,如果所有M都阻塞了,那些本可以运行的任务G将没有系统资源运行。
封装系统调用entersyscallblock,使得进入阻塞的系统调用前执行releaseP和handOffP,即剥夺M拥有的P的mCache。如果P本地队列还有G,P将去找别的M或创建新的M来执行,若没有则直接放进pidle全局链表。当有新的G加入时可以通过wakeP获取这个空闲的P。
1 | func entersyscallblock(dummy int32) { |
另外,进入非阻塞的系统调用entersyscall时会将P设置为Psyscall。监控线程sysmon在遍历P,发现Psyscall时将执行handOffP。
抢占调度
当前G只有涉及到锁操作,读写channel才会触发切换。若没有抢占机制,同一个M上的其他任务G有可能长时间执行不到。
go没有实现像内核一样的时间分片,设置优先级等抢占调度,只引入了初级的抢占。监控线程sysmon会循环retake,发现阻塞于系统调用或运行了较长时间(10ms)就会发起抢占preemption(P)。
1 | func retake(now int64) uint32 { |
抢占只是把G的stack设置为stackPreempt,这样下一次函数调用时检查栈空间会失败,触发morestack。morestack中发现是stackPreempt会触发goschedImpl,通过dropg将M和G分离,然后从全局获取runq重新进入schedule循环。
1 | func gopreempt_m(gp *g) { |
负载均衡
内核线程M不是从全局任务队列中得到G,而是从M本地维护的G缓存中获取任务。如果某个M的G执行完了,而别的M还有很多G,这时如果G不能切换将造成CPU的浪费。
P设计为内存连续的数组,为实现work stealing提供了条件。即当P的G队列为空时,P将随机从其它P中窃取一半的runnable G。这部分实现在M的启动函数mstart当中,作为schedule循环的一部分,持续的从各种渠道获取任务G。
1 | func findrunnable() (gp *g, inheritTime bool) { |
栈分配
G的栈空间怎么分配,太大会造成浪费,太小又会溢出,因此需要栈可以自动增长。
G初始栈仅有2KB。在每次执行函数调用时调度器都会检测栈的大小,若发现不够用则触发中断。检查方法是比较栈指针寄存器SP和g->stackguard,如果SP更大则需要调用runtime.morestack扩展栈空间。其中morestack保存了当前现场到m的morebuf域,并调用runtime.newstack。
newstack需要切换到调度器栈m->g0去调用。它分配一个大的新空间,将旧栈中的数据复制过去。这个过程中要保证原来指向旧栈空间的指针不会失效,要对这些指针进行调整。
1 | func newstack() { |
新栈复制好以后仍然是调用gogo切换栈执行,这跟schedul中gogo到G函数一样。栈切换完成以后通过JMP返回到被中断的函数。直到遇到return才会返回到runtime.lessstack进行栈收缩。G的任务return时将返回到goexit清理现场。