gRPC-Balancer
gPRC没有提供Balancer的实现,但给出了接口。基本原理是gRPC的client端为它要访问的target地址维护了ClientConn。在没有Balancer时这个ClientConn的conns只有一个address和它对应的一个连接,当有Balancer时Balancer会给出target对应的一组地址列表,ClientConn要维护这组地址对应的所有连接。
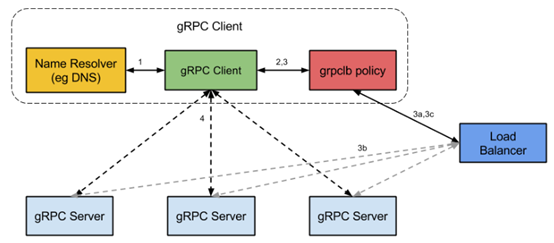
- Balancer根据Resolver去Watch具体target的地址信息变化,并通知clientConn更新它的缓存。这是通过Balancer的Start&Notify方法实现的,它初始化Resolver,并开始Watch注册中心,Watch的事件将用来更新Balancer自身的addr缓存,并通过Notify通知clientConn更新整个连接池的缓存。
- 每次调用时Balancer通过特定的策略给出具体地址,client从conns中找到对应的conn去transport。这是通过Balancer的Get方法实现的,Get方法从已建立好的Balancer的addrs中根据不同的lb策略选择这次的addr返回。
- Balancer在缓存中维护地址列表,并提供接口给clientConn根据连接状态,更新地址列表中的地址状态。
1 | type ClientConn struct { |
1 | type Balancer interface { |
总结下来就是Balander需要域名解析Resolver提供的Watcher,还需要负载均衡策略policy(selector)。如图所示,gRPC没有提供Resolver的实现,就是没有提供服务注册发现监听的实现,需要开发者结合etcd consul等注册中心自己实现该接口。lb策略gRPC有个roundRobin的实现可供参考。
ClientConn & Balancer
简单总结gRPC客户端在Dial时负载均衡相关操作。Dial的过程会返回ClientConn,其中重要的数据成员是维护了一组对应target地址的连接conns map[Address]*addrConn。在Dial中开启goroutine完成了balancer的Start,即启动resolver并开始watchUpdates。同时开始lbWatcher,开始维护clientconn的连接池。
1 | go func() { |
Notify返回的ch是balacer提供给外部的全量addrs,lbWatcher每次都对比addrs和目前自己维护的clientconn,新增的重新建立连接resetAddrConn,删掉的tearDownConn。
1 | func (cc *ClientConn) lbWatcher(doneChan chan struct{}) { |
最后在clientConn在getTransport时,通过balancer.Get可以获取满足lb策略的addr,并最终在ClientConn维护的conn缓存中获取对应的连接。
Start
gRPC给了一个RoundRobin的实现,其中addrs是所有客户端要连接的地址。addrCh是用来通知gRPC内部client地址列表的chan,也就是上面Notify()返回的chan。waitCh在无地址可连接时block。next指向Get方法返回的addrs id。
1 | type roundRobin struct { |
start方法通过Resolve获取对应target的watcher,并开始watchAddrUpdates。watcher的Next方法在没有事件时block,一旦有updates产生,balancer将按事件类型更新本地的addrs缓存,并把全部addrs发到addrCh上,这个chan通过Notify这个Balancer的方法对外提供读取。
slice copy的用法是slice长度较小的决定,copy是删除slice元素的一个简单方法
1 | func (rr *roundRobin) Start(target string, config BalancerConfig) error { |
gRPC并没有提供Resolver的实现,只是给出了它的接口。可以外部通过对接etcd consul等注册中心来实现resolver接口,它返回对特定target的Watcher,watcher的Next给的是一次增量事件,需要balancer自己解析事件类型和维护本地的addrs列表。
1 | type Resolver interface { |
Up Notify Close
up方法是用来set连接状态的。下面节选了一段resetTransport的实现,balancer的主要作用是在clientconn维护连接池时,同步的更新balancer维护的addrs的连接状态,即是否connected,并且返回将addrs状态设为非连接的方法ac.down。
1 | func (ac *addrConn) resetTransport(closeTransport bool) error { |
Notify就是把watchAddrUpdates维护的全量adrrs 返回给lbWatcher,供上层维护clientconn。Close会关掉addrch和waitch,同时要关掉resolve的watcher。
1 | func (rr *roundRobin) Notify() <-chan []Address { |
Get
Get方法按负载均衡策略返回balancer某个状态为connected的addr,gRPC给了个rouncrobin的例子,通过next这个index来确定每次连接的addr。如果没有addr,可以不block,直接返回导致调用失败,也可以利用wiatCh来做for-select,直到上层在连接恢复时调用Up,可以 close(rr.waitCh)唤醒这个block,代码省略。
1 | func (rr *roundRobin) Get(ctx context.Context, opts BalancerGetOptions) ( |
Selector
总结完Balancer的使用和基本实现,因为负载均衡策略和Resolver可以按接口自行扩展,所有将这两部分单独说说,resolver的实现下一节写服务注册中心再说吧,这个库grpc-lb可以参考。它的rouncrobin就是gRPC的实现,只是把balancer内部跟策略相关的重新封装成了Selector,在此基础上重写了Get方法实现了几种负载均衡策略。
1 | type Selector interface { |
其中Add、Delete用来watchAddrUpdates时更新selector缓存。AddList用于给Notify返回全量addrs。Up、Down用来更新addr的connected状态。Get用来给不同lb-selector实现选择算法。这里的Put是作者给每个addr的负载load信息自减的方法。详见grpc-lb。
random
在gRPC的Selector中包含实现Selector接口的baseSelector要考虑当前connected的状态,去除这些跟框架相关的代码后,就是rand.Int() % len(addrs)。这里通常都要初始化随机种子,否则每次获取的随机值都一样,通常用当前时间来初始化一下种子rand.Seed(time.Now().UnixNano()),保证种子的随机。
官网文档里有提示 Seed should not be called concurrently with any other Rand method. 如果并发的seedrand.Seed踩坑提到会导致goroutine暴增。
1 | func init() { rand.Seed(time.Now().UnixNano()) } |
roundrobin
轮询就是通过维护一个next作为index,每次+1完成的。代码例子经过调整,省去了很多,在实际的例子中要注意mux的使用,尽量使加锁范围小。还有问题是从balancer的watchUpdates而获取的addrs列表动态变化,缓存维护了connected状态可以尽量避免访问到已经teardown的实例,但仍然要提供容错和backOff机制。
1 | var next int |
latency or leastaction
根据client端与server端实际连接动态调整addr的策略。leastaction需要额外统计当前与每个服务实例的连接数,选择服务实例连接数最少的访问。latency要计算与每个服务实例的平均时延,选择平均时延最小的实例访问。
go-chassis有类似实现,主要是通过transport统计latency,由latency_strategy管理和保存平均时延
consistent hash
这个以后再写一篇单独的分析吧,这里简单总结个大概。一致性hash是要解决当节点数量变化时,原有的数据来源hash到的节点(cache)基本不一致(失效)的问题,通过一致性hash希望将节点变化时,数据迁移量降到最低。
基本原理是hash ring,即将节点node本身也hash到环上,通过数据和节点的hash相对位置来决定数据归属,因此当有新node加入时只有一部分的数据迁移。但事实上,这样的一致性hash导致数据分布不均匀,因为node在hash ring上的分布不均匀。分布不均匀的问题通过引入虚拟节点来解决,虚拟节点是均匀分布在ring上的,数据做两次match,最终到实际节点上。这样来保证数据分布的均匀性。
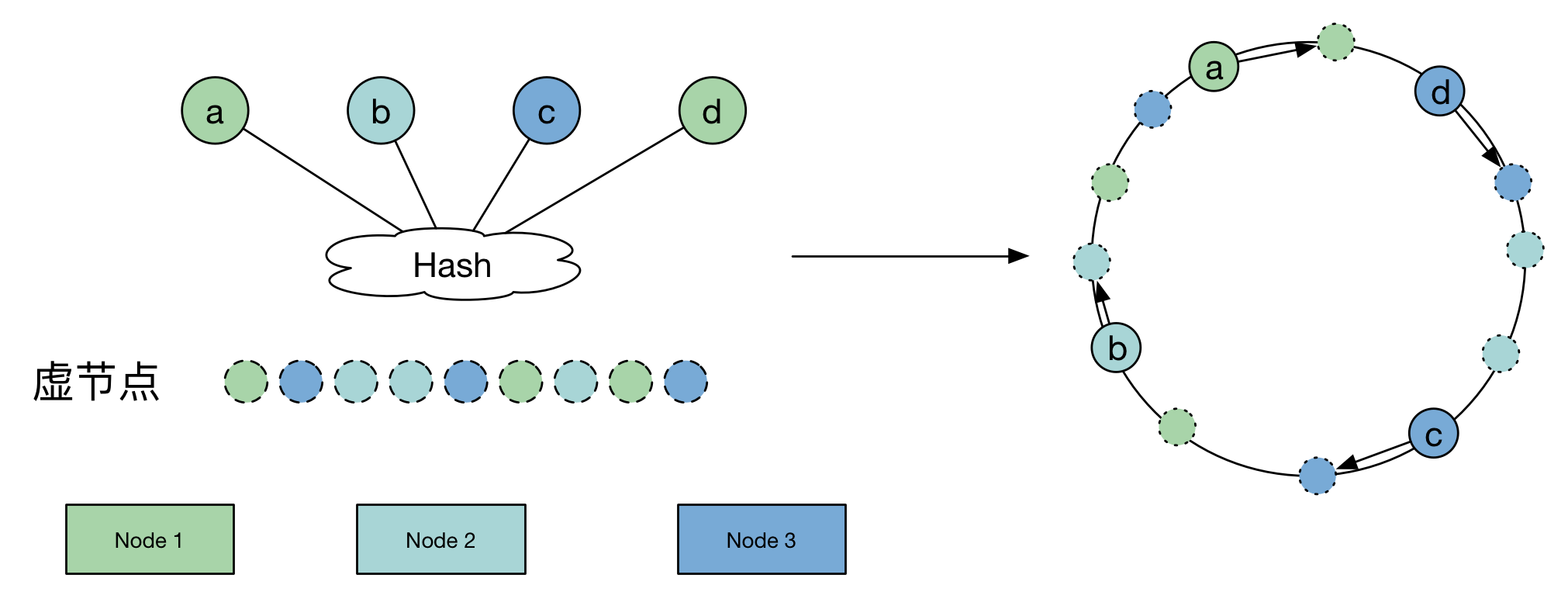
groupcache有个consistenthash的实现,royhunter有个带虚拟节点的实现。以groupcache为例,默认HashFunc是crc32.ChecksumIEEE。keys相当于是hashRing,replicas相当于虚拟节点。
1 | type Hash func(data []byte) uint32 |
在添加节点时,为每个节点创建replica个虚拟节点,并计算虚拟节点的hash值存入hashring,也就是keys这个slice中,同时把这些虚拟节点的hash值与node的对应关系保存在hashMap。最后给keys排个序,就像在环上分布,顺时针递增一样。
1 | func (m *Map) Add(keys ...string) { |
Get方法是获取数据对应的节点,相当于负载均衡中源ip对应到哪个节点或哪个cache。计算数据的hash,并在hashRing上二分查找第一个大于hash的虚拟节点,也就通过hashMap找到了对应的真实节点。
1 | func (m *Map) Get(key string) string { |
session stickiness
会话保持是指在负载均衡器上有一种机制,在作负载均衡的同时,还保证同一用户相关连的访问请求会被分配到同一台服务器上。 一致性hash类似这个问题,可以保证同一IP来的连接都hash到同一个node,在node动态变化时会带来某一些session失效。
go-chassis有基于cookie做session保持的一种实现,即配置lb策略为session_stickiness时,每次transport后都会checkForSessionID。若req有而sessionCache没有,则生成sessionID写入response的cookie。客户端可以从response中的cookie拿到sessionID,在下一次调用时加入到req的header中,在lb时将从sessionCache找到对应的实例地址。若req和cache都有则更新cache中的timeout时间。
同时支持计算该session-node失败次数,超过默认5次失败,则删除sessionCache中对应的记录,然后下次请求将roundrobin调度到另一个节点,然后开始会话保持。